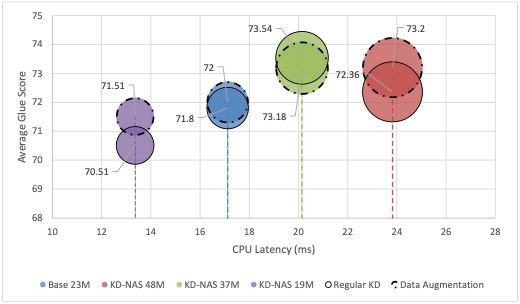
Large pre-trained language models have achieved state-of-the-art results on a variety of downstream tasks. Knowledge Distillation (KD) of a smaller student model addresses their inefficiency, allowing for deployment in resource-constraint environments. KD however remains ineffective, as the student is manually selected from a set of existing options already pre-trained on large corpora, a sub-optimal choice within the space of all possible student architectures. This paper proposes KD-NAS, the use of Neural Architecture Search (NAS) guided by the Knowledge Distillation process to find the optimal student model for distillation from a teacher, for a given natural language task. In each episode of the search process, a NAS controller predicts a reward based on a combination of accuracy on the downstream task and latency of inference. The top candidate architectures are then distilled from the teacher on a small proxy set. Finally the architecture(s) with the highest reward is selected, and distilled on the full downstream task training set. When distilling on the MNLI task, our KD-NAS model produces a 2 point improvement in accuracy on GLUE tasks with equivalent GPU latency with respect to a hand-crafted student architecture available in the literature. Using Knowledge Distillation, this model also achieves a 1.4x speedup in GPU Latency (3.2x speedup on CPU) with respect to a BERT-Base Teacher, while maintaining 97% performance on GLUE Tasks (without CoLA). We also obtain an architecture with equivalent performance as the hand-crafted student model on the GLUE benchmark, but with a 15% speedup in GPU latency (20% speedup in CPU latency) and 0.8 times the number of parameters.